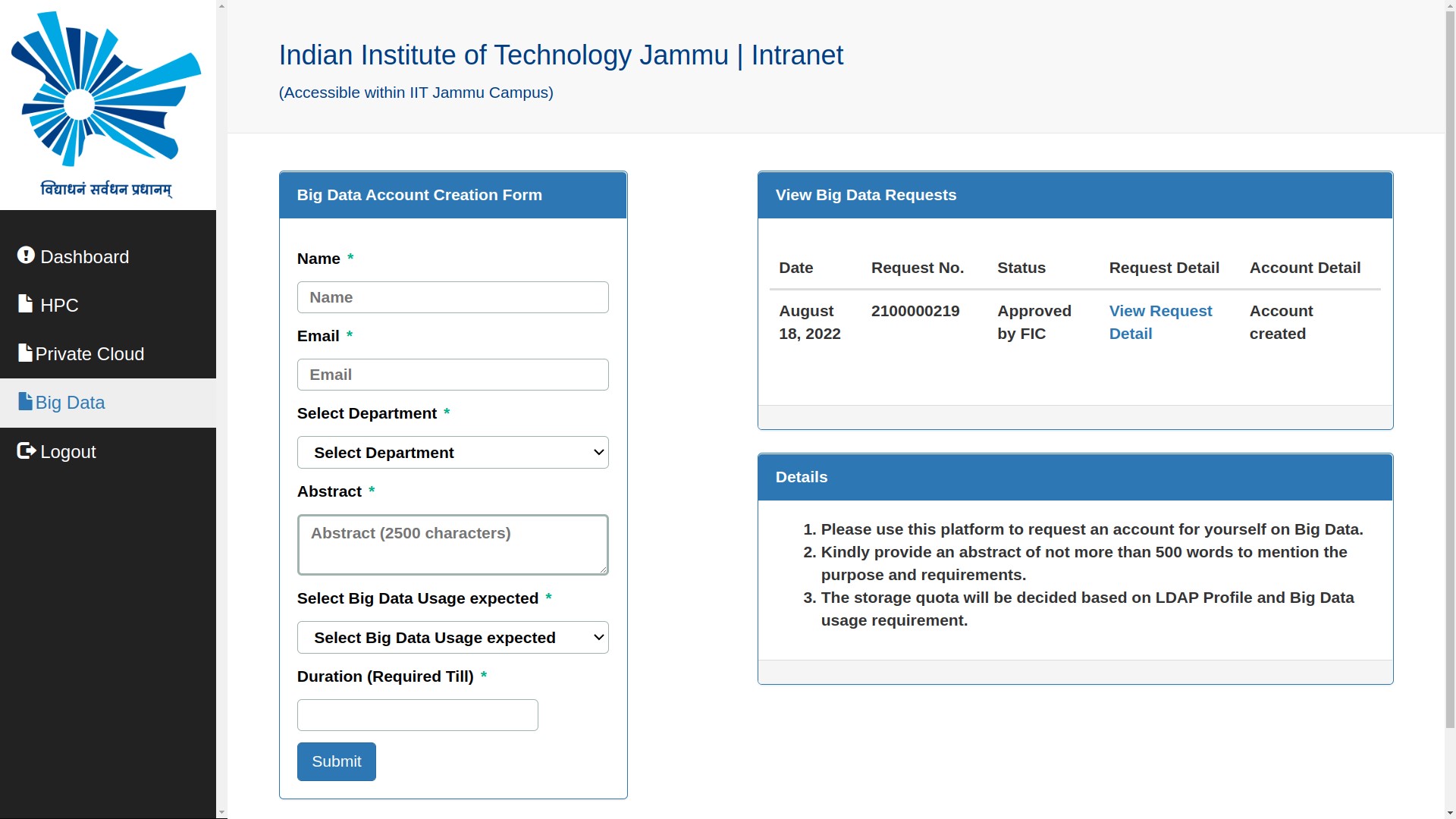
You will be provided user credentials after approval from authorities to access your Big data
user account:
Credentials: USERNAME, PASSWORD, IP_Address.
Write the mapper and reducer code that you want to run on the Hadoop cluster.
You can follow the link for the word count program.
Click
Here
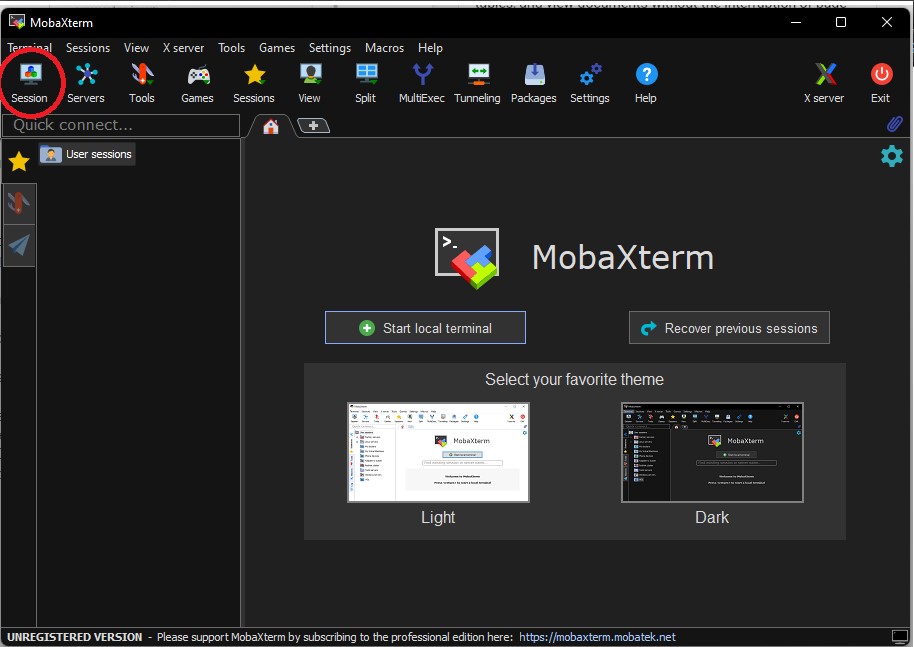
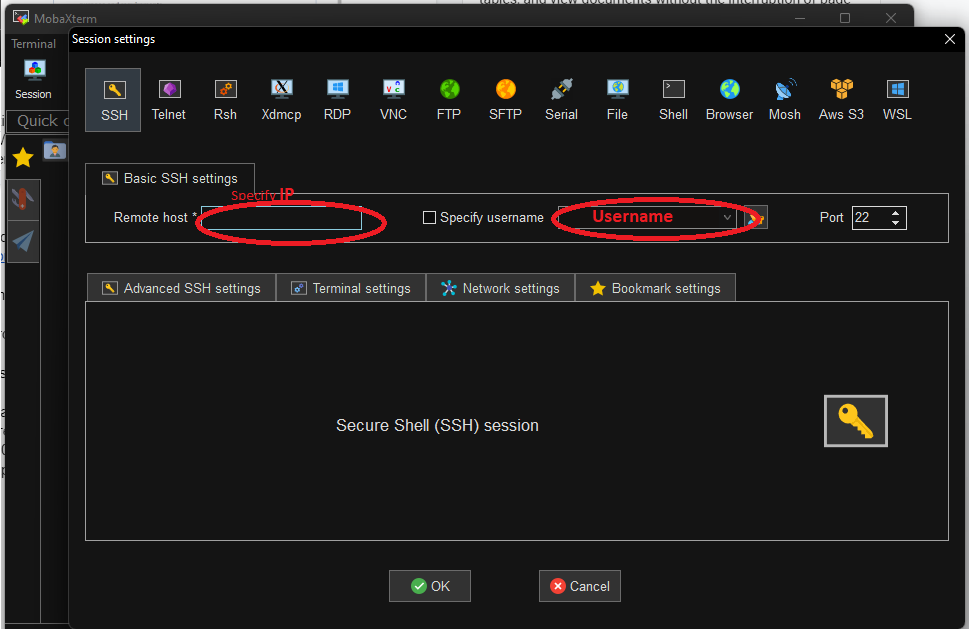
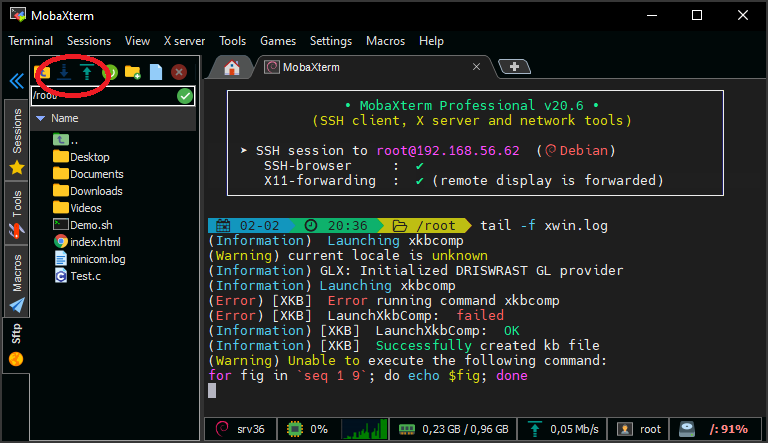
Upload the mapper and reducer to your BigData user space using mobaXterm.
Run map reduce program for wordcount:
Create a file data.txt with sample data
Upload data.txt to HDFS(hadoop distributed file system)
Create a directory in HDFS:
hdfs dfs -mkdir data
Put data.txt(stored in local) into that folder in HDFS:
hdfs dfs -put /home/USENAME/data.txt data
hdfs dfs -put .
Run mapper.py and reducer.py on data.txt to perform word count.
hadoop jar /usr/hdp/3.1.4.0-315/hadoop-mapreduce/hadoop-streaming.jar -file
mapper.py -mapper mapper.py -file reducer.py -reducer reducer.py -input
input/data.txt -output output
Brief Explanation:
hadoop jar
-file
-mapper
-file < Location of mapper in local>
-reducer
-input < location of input data in HDFS>
-output
Example for mapper.py and reducer.py
mapper.py
#!/usr/bin/python
import sys
#Word Count Example
# input comes from standard input STDIN
for line in sys.stdin:
line = line.strip() #remove leading and trailing whitespaces
words = line.split() #split the line into words and returns as a list
for word in words:
#write the results to standard output STDOUT
print'%s %s' % (word,1) #Emit the word
reducer.py
#!/usr/bin/python
import sys
from operator import itemgetter
# using a dictionary to map words to their counts
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
line = line.strip()
word,count = line.split(' ',1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word,current_count)
hadoop jar /usr/hdp/3.1.4.0-315/hadoop-mapreduce/hadoop-streaming.jar -file
mapper.py -mapper mapper.py -file reducer.py -reducer reducer.py -input
input/data.txt -output output/output746
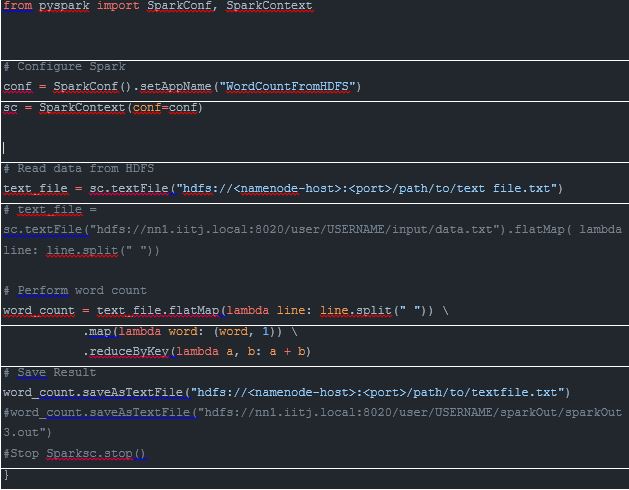
How to use Spark?
Please refer to the document where how to use the Big DATA cluster is explained, and login to
your user account.
Spark is pre-installed on the user account.
Type the command pyspark on cmd. To access the python spark shell. It is a python interface to
use the spark. You can use other programming language interfaces as well like scala,R etc.
There are Data processing and Machine Learning libraries available in pyspark, which can be used
as well.
Store dataset on HDFS which can be of very big size and can be used in a pyspark to process.
Write the pyspark code which you want to run on the BigData cluster.
Save the file on local as “wordCount.py” and then can be executed by :
Spark-submit wordCount.py
You can refer to link for Examples of spark code: spark.apache.org
Word Count example Code: